
Core ML の stable diffusion を使ってみた

stable diffusion の雑感
stable diffusion のオープンソース化は、2022 年 8 月 22 日だった。その前日に note の偉いひとが、「世界が変わる」みたいな大げさなこといっていて失笑したりしたのだが、ちっとも大げさじゃなかった。慧眼だった。筆者が馬鹿だった。世界は本当に変わったのかもしれない。
約一ヶ月半後に、NovelAI が出てきて、日本列島を震撼させる。Anything v3 が出てきたのがその一ヶ月後くらい。22 年 11 月だった。
もうその辺から楽しいわちゃわちゃが始まって、祭りはまだ終わってない。全世界的にお祭り状態。朝起きると、どこかの誰かが新しいなにかを作っている。最近では controlNet でまたひとつ局面が動いた感じがある。筆者は消費するだけの存在なのに(AI による画像の生成は、創作というより消費の匂いがある)、追いかけるのが大変なくらいだ。
Mac における stable diffusion も進化を続けた。
筆者は 9 月ごろ初めて M1 MacBook Air で stable diffusion を試してみた。そのころは CPU で動いていて、一枚の画像を作るのに 10 分くらいかかっていたと思う。
まもなく Apple シリコン Mac の GPU が使えるようになり、まぁ CUDA ほど速くはならないものの、使える速度になってきた。768 x 512 の画像が 20 steps で一分以内に出来上がるのである。
Neural Engine
Mac は nvidia の GPU を使ってないので、不利に立たされているのだが、希望がないでもなかった。Neural Engine である。最近の Mac には Neural Engine というものがチップに搭載されており、動画のエンコードなんかはこれのおかげで滅茶苦茶に使いやすくなった。
その Neural Engine で AI のデカいデータを扱える、と聞いたことがあって、これを画像生成に使えないのかなぁ、と筆者は鼻クソほじりながらぼんやり思っていた。
そしたら、本当にそんなのが出てきた。
Core ML stable diffusion と、それを利用した hugging face 公式の Diffusers for Mac である。
👨🚀 GitHub – apple/ml-stable-diffusion: Stable Diffusion with Core ML on Apple Silicon
🐶 Diffusers on the Mac App Store
v 1.0 を喜び勇んで使ってみた。確かに速くなっていた。が、全体的な感想としては正直がっかりだった。
速度が上がった、といってもそこまで目覚ましくない。場合によっては GPU のほうが速いんじゃないかな、まである。なにより不自由なことに、画像のサイズを指定できないのである。モデルの追加も出来ない。
「これは実験的なものだな」
と思って放ったらかしにしていた。
Diffusers v1.1
先日、Diffusers.app が version 1.1 になったと、AAPL.ch さんの記事で知った。
さっそく試してみたところ、512 x 512 の画像が 25 steps で、10 秒ほどで出力された。
(Neural Engine より GPU のほうが速い機種もある。上の記事に詳しい)
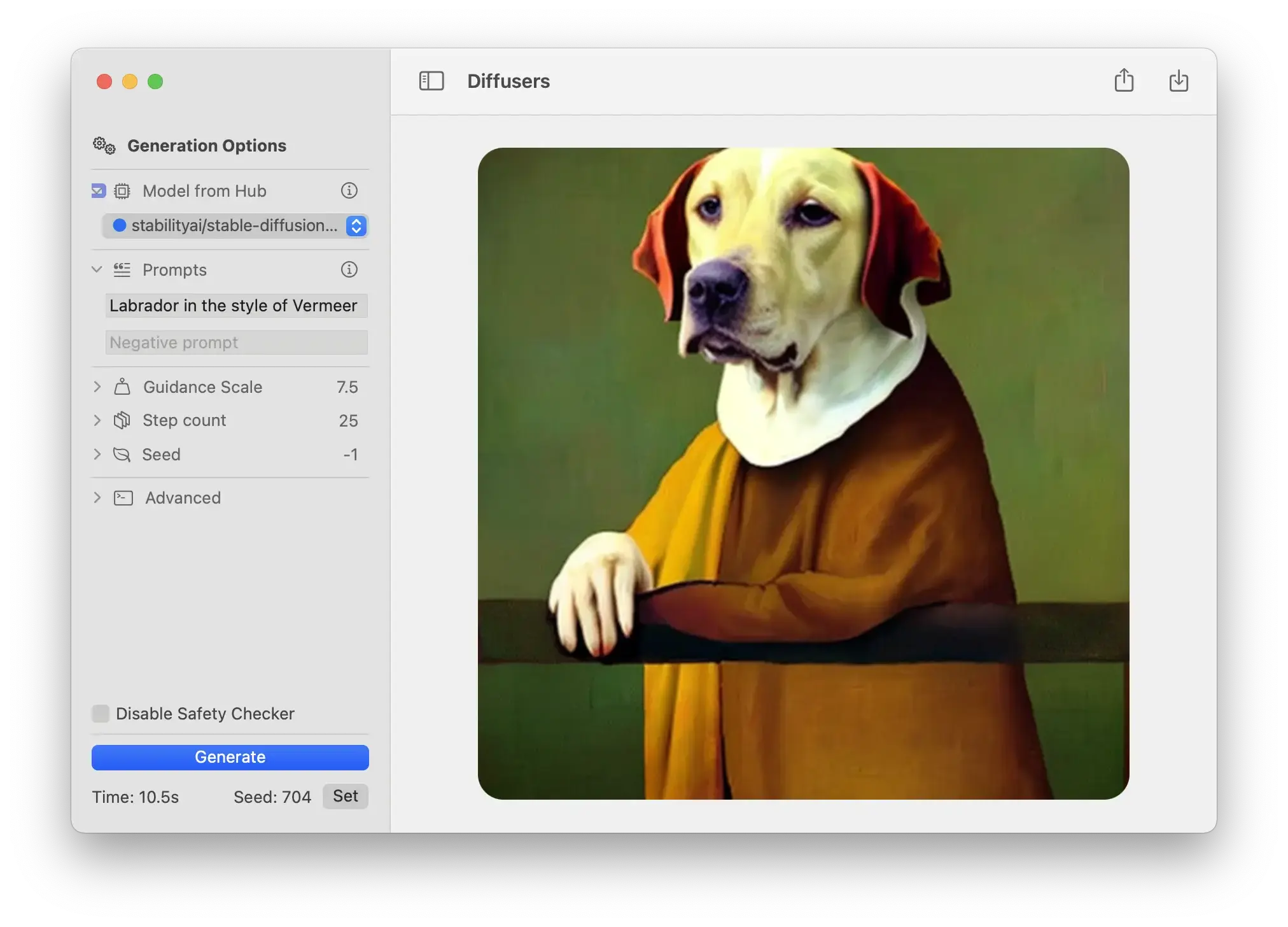
こうなってくると意味合いが変わってくる。
デカいファンをぶん回すデスクトップ PC の話じゃないのである。ファンレスのうっすいノートパソコン、M2 MacBook Air(8コア、16GB) でのスコアなのだ。これはなかなかのものではあるまいか。
Neural Engine のおかげか、筐体もあまり熱くならない。
Core MLは、Appleのハードウェアを活用し、メモリ占有量と電力消費量を最小限にしながらも、幅広い種類のモデルがオンデバイスでパフォーマンスを発揮できるように最適化されています。
Core MLの概要 – 機械学習 – Apple Developer
ということらしい。
Mochi Diffusion
Diffusers.app ではモデルの追加が出来ないようだ。
しかし、同じく Core ML stable diffusion を利用した Mochi Diffusion なら、さまざまなモデルを追加できる。
🐱 GitHub – godly-devotion/MochiDiffusion: Run Stable Diffusion on Mac natively
Core ML Diffusion においては、ckpt や safetensors ファイルがそのままでは使えない。変換が必要になる。
人気のモデルはすでに変換されて hugging face にアップロードされている。
split_einsum というバージョンの場合はサイズが 512 x 512 で、Neural Engine を使用して画像を生成する。
original バージョンは 768 x 512 や 512 x 768 などのサイズが用意されており、CPU と GPU で画像を生成する。繰り返しになるが、画像のサイズを指定できない。必要なサイズの画像を作ってくれるモデルをダウンロードする形式だ。
また、以下のアプリでモデルを変換できるらしいのだが、未確認だ。
🕶️ Guernika/CoreMLStableDiffusion · Hugging Face
ダウンロードした zip ファイルは、解凍して「書類」フォルダに生成される MochiDiffusion フォルダ内、models フォルダに移動する。パスで書けば Documents/MochiDiffusion/Models がモデルの置き場となる。
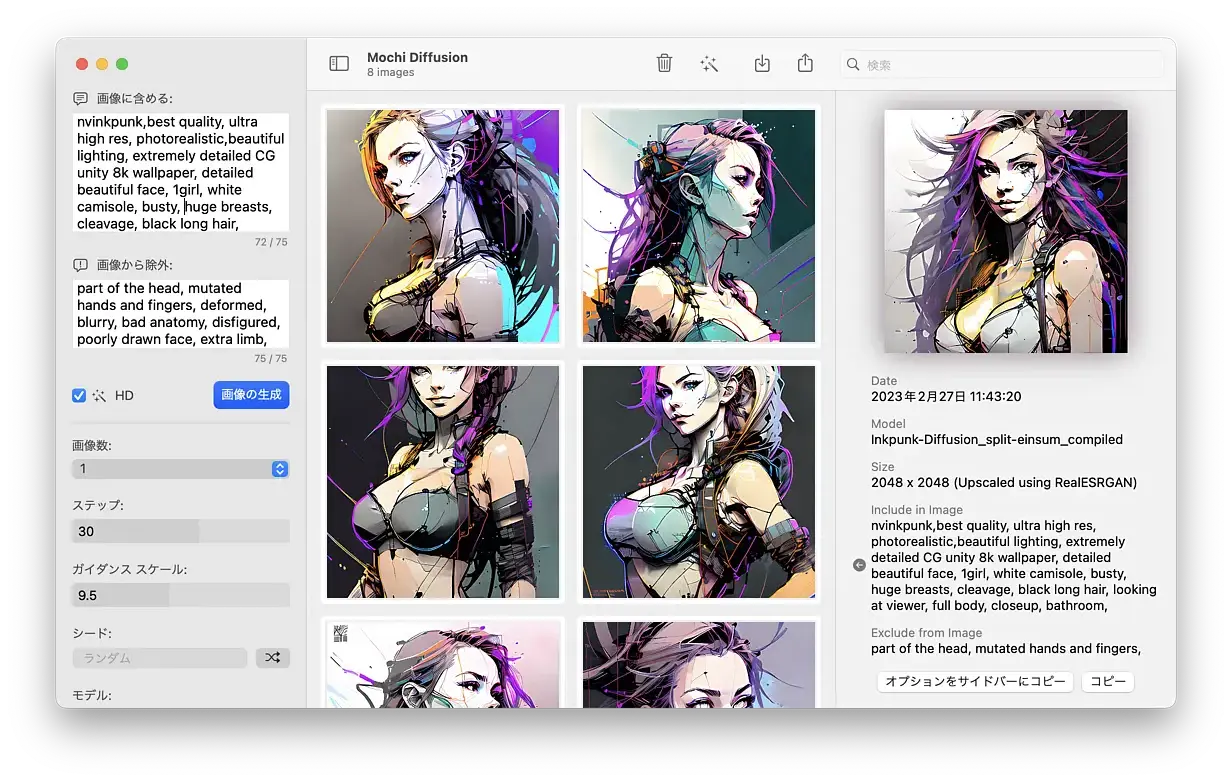
Mochi Diffusion もさすがに速い。縦横 512 ピクセル、25 steps で 15 秒くらいか。
画像 10 枚を出力するのに 2 分半ほどだ。
v 2.5 からは Documents/MochiDiffusion/images 内に画像が出力される。
HD というチェックボックスをチェックすると、画像を 2048 ピクセルにアップスケールしてくれる。
メニュー等は日本語化されているし、seed やプロンプトを左のサイドバーに反映することも出来る。なかなか良く出来てると思う。
Apple は対応するだろうか
Neural Engine はなるほど凄い。
しかし画像サイズを指定できないのはいかにも歯痒い。Apple はこれに対応するだろうか。 ご自慢の M1、M2 チップの非力さをあらわしているようで、画像生成の遅さは Apple のプライドを傷つけるだろう。しかし、「stable diffusion? そういう野良なものは個別に対応しないよ。キリねぇから」とキレてくる可能性も十分にある。 Core ML を用意してやったろ? みたいな。 もし対応してくれるなら、出来ればソフトウェア的にやって欲しいところだ。ハードウェア的にやられても買い替える金なんかないんだから。でも Apple はハードで稼ぐ PC メーカーだからなぁ。拝金主義だしなぁ。難しいかもしれんね。
追記 2023 03 02
この記事、調べてみたら全然違った。
なんでこう、ちょっと調べたらわかること間違えるかね。
正確には、Apple が Ventura 13.1 から Core ML Stable Diffusion に対応したんだ。
未対応なのかと勝手に思ってた。それどころか、Apple がじきじきに、Core ML Diffusion を公開してくれた、ということみたい。
🍎 Stable Diffusion with Core ML on Apple Silicon – Apple Machine Learning Research
拝金主義だからソフトウェア的にはなにもしねぇだろ、的なことをいってしまい、誠に申し訳ありませんでした。
でもこれですっきりした。こんな感じなんだな。steps の工数を 10 ぐらいにすれば、Diffusers.app で爆速体験できる。画像の生成まで 5 秒くらい。まぁ、十分か。