
M1 MacBook Air に stable diffusion をインストールしてみた

テキストで指示した内容の画像を AI が生成するという「Stable Diffusion」がなにかと話題だ。
面白そうなので筆者も MacBook Air late 2020 にインストールしてみた。
結果からいうと下の Gigazine さまの記事のように、Google が提供する python の実行環境「Colaboratory」を利用するほうが圧倒的に速い。
🔗 画像生成AI「Stable Diffusion」を低スペックPCでも無料かつ待ち時間なしで使う方法まとめ – GIGAZINE
上記のやり方なら、30 秒くらいで画像が生成される。
ローカルだと 10 分くらい平気でかかる。
とはいえ、ローカルでやってみたいじゃん、という思いもあり、やってみたのだ。
筆者は無知だし馬鹿なので、以下に書くことの説明はできない。「同じようにやったけど、出来ねぇよ」という場合もあるかと思う。その場合はすみません。
この記事は 2022 年 8 月現在のものである。
python のバージョンは 3.8 とか 3.9 ぐらいあれば大丈夫だと思う。
また 6〜7Gb くらいの SSD の空きが必要となる。学習済みのデータが糞でけぇ。
準備
stable diffusion での画像生成は python を用いるので、python の仮想環境を設置するのが良いと思う。やり方は簡単だ。デスクトップとか、適当なところにフォルダをこしらえて、そこへ移動する。
mkdir ~/Desktop/'python-test'
cd ~/Desktop/python-test仮想環境を準備するために venv というコマンドを使う。
python3 -m venv env実行すると、先ほどこしらえたフォルダの中に「env」というフォルダが生成される。env のなかを見ると、pip 等のバイナリがインストールされているのがわかる。
仮想環境を有効にするには、souce で activate というのを読みこませる。
source env/bin/activateこれでターミナルの表示の先頭に (env) と入っていれば成功だ。
筆者の場合は以下のようになる。
(env) 19:20 bakurou@MacBook-Air-2 ~/Desktop/python-test
[>_ ] > python3
Python 3.8.2 (default, Apr 8 2021, 23:19:18)deactive というコマンドを実行すれば仮想環境から抜けられる。
仮想環境を整えておけば、いろいろインストールしてわけがわからなくなっても大丈夫。作成したフォルダ、この場合は python-test フォルダをゴミ箱に捨てて、いちからやり直せばいいわけだ。
python の仮想環境については下記の記事で学ばせていただきました。ありがとうございます。
🔗 venvでpythonの仮想環境を作る!アクティブ化など使い方まとめ | プログラミングを学ぶならトレノキャンプ(TRAINOCAMP)
Hugging-Face のトークンを取得する。
あとは、上述した Gigazine さまの記事のまんまである。
画像生成AI「Stable Diffusion」を低スペックPCでも無料かつ待ち時間なしで使う方法まとめ – GIGAZINE
この記事の前半にめちゃめちゃ詳しいトークンの取得方法が書いてある。
メールアドレスとパスワードでサインアップする必要があるものの、やってみればわかる通り、凄く簡単だ。
diffusers 等のインストール
トークンが取得できたら、仮想環境内にいろいろとインストールしていく。
これもほぼ Gigazine さまの記事のまんまである。
ターミナルで以下を実行する。
pip install diffusers scipy ftfyGigazine さまの記事だと diffusers==0.2.4 とバージョンが指定されているのだが、試したところうまくいかなかった。指定なしでインストールしたほうがいいように思う。
実行すると付随するプログラムも一緒にインストールされる。
続いて transformers というのもインストールする。
pip install transformersが、筆者の M1 MacBook Air の場合、以下のようなメッセージが出てインストールできなかった。
Could not build wheels for tokenizers, which is required to install pyproject.toml-based projectsググってみたところ下記の非常にありがたい記事にゆきついた。
🔗 transformersのインストール – 個人的なプログラムドキュメント #芹生(せりう)
rust というのをインストールするらしい。
自宅の Intel 搭載の Mac mini だと素直にインストールできたので、すべての Mac でエラーが出るわけではなさそうだ。
動作確認の準備
ここからは python を呼び出しての作業となる。
python3 と入力してリターンキーを押す。以下のようになるはずだ。
(env) 19:20 bakurou@MacBook-Air-2 ~/Desktop/python
[>_ ] > python3
Python 3.8.2 (default, Apr 8 2021, 23:19:18)
[Clang 12.0.5 (clang-1205.0.22.9)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>この状態のまま Hugging Face のトークンを入力する。
>>> YOUR_TOKEN="発行したトークン"続いて、たぶん stable diffusion のなにかを呼び出す以下を実行する。
>>> from diffusers import StableDiffusionPipelineさらに、以下を実行する。
>>> pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=YOUR_TOKEN)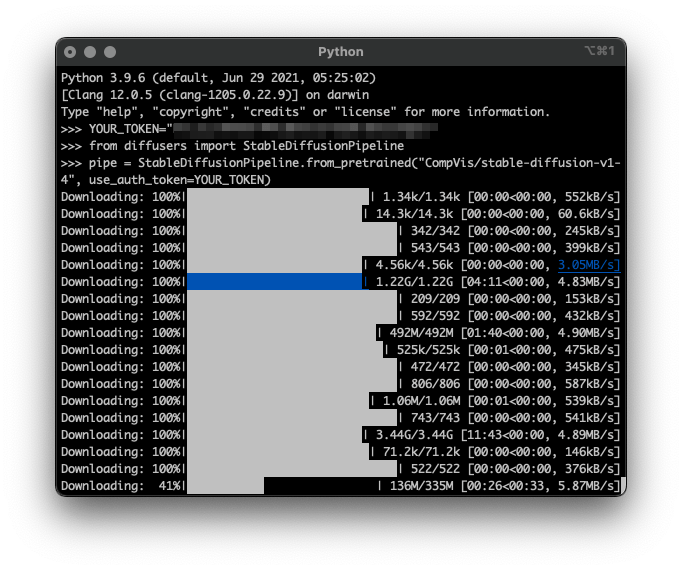
初回は大量のデータをダウンロードするはずだ。けっこう時間がかかる。
二回目以降も、ダウンロードこそしないものの、ダウンロードしたデータをコピーするのか、ちょっと時間がかかる。
このデータは、仮想環境にしたフォルダの中にダウンロードされるわけではなさそうだ。
たぶんだけど、ホームフォルダ/.cache/huggingface にあるのがそれっぽい。画像生成に飽きたら、削除しちゃうのがいいんじゃないかな、たぶん。
画像の生成
ダウンロードが終わったらいよいよ画像の生成だ。
どんな画像を作るか指定するテキストは prompt という変数に書く。
>>> prompt = "cute cat play with ball"そして画像生成。
>>> image = pipe(prompt)["sample"][0]これがまた時間かかる。
0it とかいう数字が 51it になるまで待たなくちゃならないんだけど、10 分くらいかかる。
GPU の関係らしいんだけど、これでも速くなったほうなのかもしれない。
数字が 51 になって、次の行に >>> があらわれたら、画像を保存する。
>>> image.save(f"cat.png")カレントディレクトリ、この場合だと python-test フォルダに、cat.png という名前で画像が保存されているはずだ。

可愛い猫ちゃんが出来ました。
python の実行環境は [ctrl] + [ D ] で抜けられる。仮想環境は deactivate と入力してリターンキーを押せば元に戻れる。
DeepLのアプリで日本語を英語に翻訳し、いろいろ試してみた。「ビキニを着た女の子がビーチで波と戯れる」を英語にすると、「Bikini-clad girl playing with waves on the beach」ということになるらしい。

あら、いいですねぇ。
いいんだけど、不気味な画像もよく生成される。身体のねじれた人や、顔の崩れた人、手足が本数が多い人など、AI なもんだから平気で人間性を侮辱する感じの画像を作ってしまう。それもまぁ面白いところか。
多少変な顔になっても違和感のない、怖い画像など向いているかもしれない。「日本のホラー映画のポスター」(Japanese horror movie posters)ってのをやってみた。


なんかちょっと格好いい。
こうして作られた画像の著作権は、コマンドを実行したひとの物になり、商用利用も出来るのだそうだ。ただ、異論もあるようなことをどこかで読んだ。このへん、議論の行方を注意して見守りたいところだ。
どうであれ 2022 年 8 月現在、M1 MacBook Air での stable diffusion は時間がかかり、米の炊き上がりを待つようにじれったい。Gigazine さまが提案するように Colaboratory を利用するのがいいだろう。
おまけ 不適切な画像を生成する
この stable diffusion、不適切な画像を生成してしまうと出力しない、という機能がある。
性的だったり暴力的だったりする画像を抑制してくれるのだ。ひとに優しい機能である。
でもね。やっぱりいろいろテストしていると、どうしてもね。えちえちな画像が生成したくなってくる。で、やらしい英単語とか調べたりしてドキドキしながら出来上がりを待つんだけど、えっちぃ画像が出来ると、真っ黒な画像しか出力してくれないのである。
この制限をとっ払うことが出来る。
🔗 Stable DiffusionのNSFWコンテンツ対策を無効化する方法 | ジコログ
上記のありがたい記事にやり方が紹介されている。神記事やね。
簡単にいうと、 env/lib/python3.8/site-packages/diffusers/pipelines/stable_diffusion/safety_checker.py をエディタ等で開く。
で、70 行〜 78 行あたりをコメントアウトするだけど、詳しくは上記の記事を参考にして欲しい。
えちえち画像、生成しまくれる。お猿さん状態でもう MacBook Air があちあちですよ。
GPU 利用して画像を生成する
下のリンクの記事に、M1 Mac で GPU を利用して画像を生成する方法が紹介されている。
🔗 Running Stable Diffusion on an Apple M1 Mac with Hugging Face Diffusers – Weights & Biases
やり方としてはまず、torch と torchvision のナイトリ版をインストールする。
pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpuうまくインストールできない場合は、一度アンインストールするのがいいかもしれない。
pip uninstall torch続いて、attention.py という書類を編集する。
書類は、
env/lib/python3.8/site-packages/diffusers/models/attention.py
という場所にあるので、エディタ等で開く
x = self.attn1(self.norm1(x)) + x という行があるはずなので、[command] + [ f ] などで検索し、x = self.attn1(self.norm1(x.contiguous())) + xと書き直して保存する。
def forward(self:BasicTransformerBlock, x, context=None):
# x = self.attn1(self.norm1(x)) + x
x = self.attn1(self.norm1(x.contiguous())) + x # <--- added x.contiguous()
x = self.attn2(self.norm2(x), context=context) + x
x = self.ff(self.norm3(x)) + x
return xここまで出来たら実行できる。python を起動し、一行ずつ以下を入力していく。
from diffusers import StableDiffusionPipeline
DEVICE='mps'
YOUR_TOKEN="hugging face のトークン"
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=YOUR_TOKEN).to(DEVICE)
prompt = "a happy dog working on a macbook air, sythwave"
image = pipe(prompt)["sample"][0]
image.save(f"happydog.png")DEVICE を設定し pipe に .to(DEVICE) をくっつけるところが、CPU を使うやり方と違うところだ。mps というのは、Metal Perfomance Shaders の略称らしい。
試したところ、確かに GPU を使っているみたいだ。
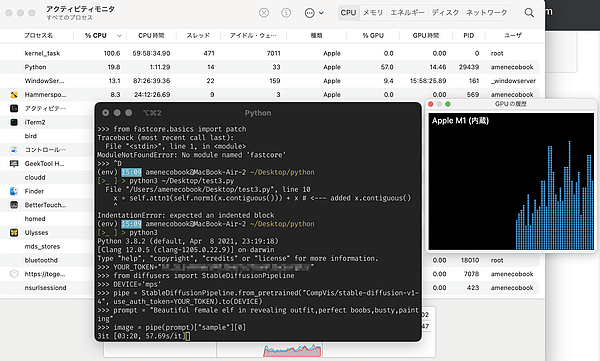
ただし筆者の環境だと 10 分ですんでいたところが、40 分近くかかってしまった。
このやり方を紹介してくれた上述の記事では、3 分程度で画像が生成された、と書いてあるので、効果がないわけではないと思う。
雰囲気の話で恐縮だが、メモリの多寡が関係してる気がする。同じ 2020 年の MacBook Air だけど、筆者のは 8G のメモリで、上の記事のひとのは 16G あるらしいから。ま、わかんないけどね。